Navigating Uncertainty

Introduction
The National Vulnerability Database (NVD) has been encountering significant challenges starting mid-February 2024, notably manifested in its failure to update the Common Platform Enumeration (CPE) information for newly disclosed Common Vulnerabilities and Exposures (CVEs).
CVE Numbering Authorities (CNA) continue to publish information about newly discovered vulnerabilities, which is collected in the CVE List maintained by the CVE Program. But these vulnerabilities descriptions come in different formats and with different level of details. NVD used to be an entity that analyzed and enriched CVE records with metrics like CVSS, CWE, and CPE, but it appears that they have stepped down from this function.
This issue introduces a significant vulnerability management challenge: accurately and automatically determining the vulnerability status of specific software versions requires precisely defined version boundaries in a machine-readable format. The backlog has grown to over 10,000 CVEs missing information on affected versions, and the NVD has not provided further updates on when this backlog might be processed.
This article explores strategies to cope with the ensuing data gaps and their broader impact on the cybersecurity landscape.
Understanding the Impact of NVD Delays
The NVD's inability to consistently enrich CVE with vulnerable configurations CPE data undermines the foundation of vulnerability assessment tools, which rely heavily on this data to accurately identify potential threats.
NVD used to have a unique “CPE rollout” feature, which basically listed all affected configurations as a separate CPE string, allowing for simple and accurate text-based search. No need for complex and intricate affected ranges analysis — just put the CPE into a search and get back a clear YES/NO answer.
Here is a short snippet from the CVE-2024-29988.
With all due critics to quality and timeliness, as well as to CPE as a naming convention, the NVD team used to undertake a massive and underappreciated effort — which apparently included lots of manual processing — to provide a foundation for all the vulnerability management industry.
The Challenge of Inconsistent Data from CNAs
Another data source that includes all CVEs is the CVE List maintained by the CVE Program. Technically, NDV is downstream from the CVE List, and builds on the information provided by the CNA.
Unfortunately, this information varies in completeness from CNA to CNA, and there is no direct option to fall back to the CVE List for CVE data to drive the vulnerability assessment and management programs.
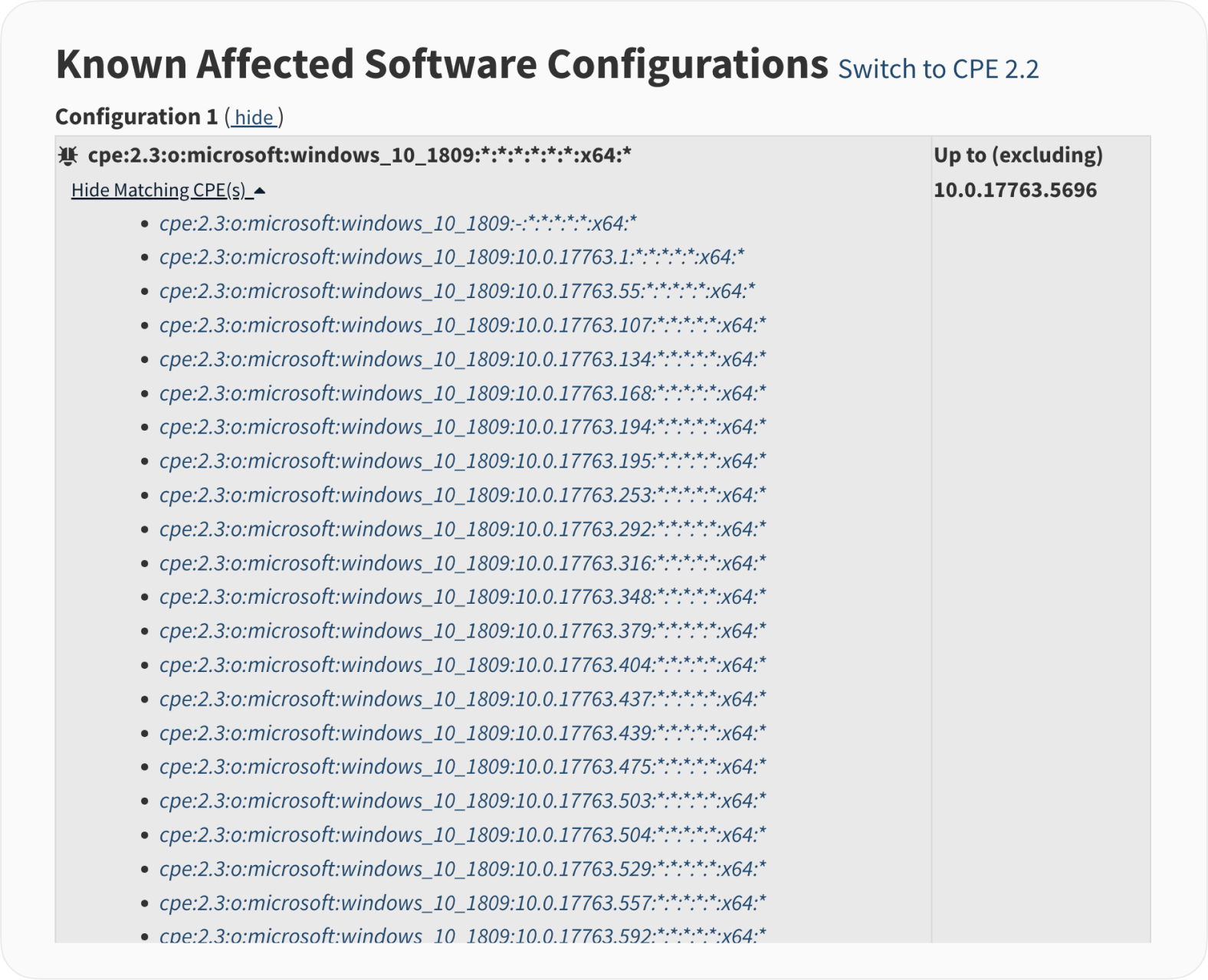
(In)completeness of the CNA provided metrics
This picture outlines the number of CVE Records that include important metrics as they are provided by various CNA and get captured in the CVE List. For simplicity, the picture shows only CVE with the CVE ID having CVE-2024 prefix — not all the CVE published in the 2024, but still a good representation of the vulnerabilities records published in the period most affected by the NVD slowdown, which is from February 12th up until now.
While most CNA provide the information about the affected configuration in one form or another, there is MITRE as a significant outlier. This makes a perfect sense, as MITRE is a CNA of the last resort and gets to publish CVE on a vast range of products. To cover them all, they probably would need to have an operation on par with NVD that was up to this task before.
Errors in the CNA provided affected configurations
As it gets clear now, NVD used to provide a lot of error correction to the CVE records. Most likely they were able to do that having an in-house team of experts, reviewing countless vulnerabilities one by one. Here are just a few examples of notorious errors that are found in the CNA provided data.
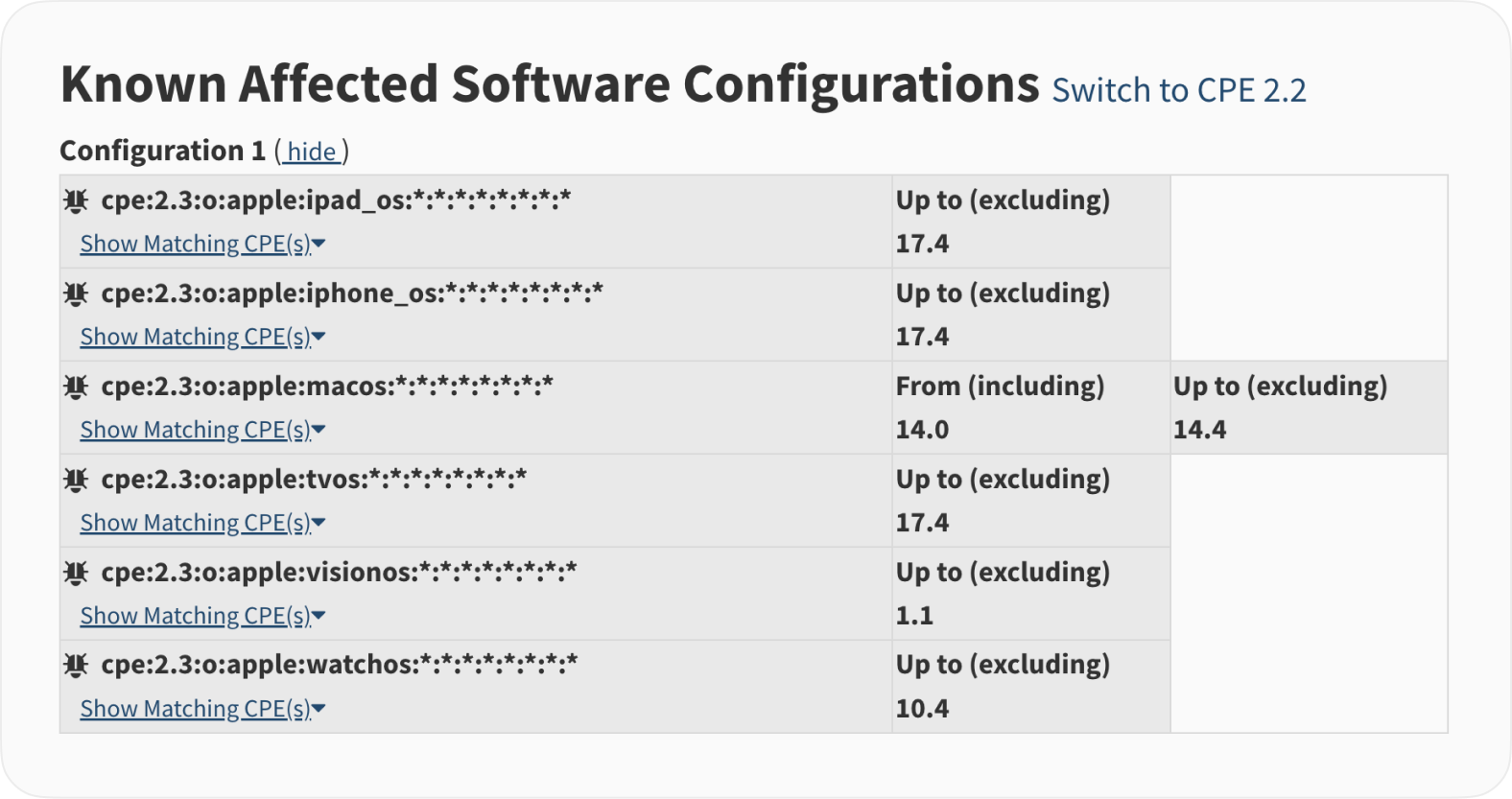
CVE-2024-23296
CVE-2024-23296 comes with a relatively non-threatening description and matching affected versions record.
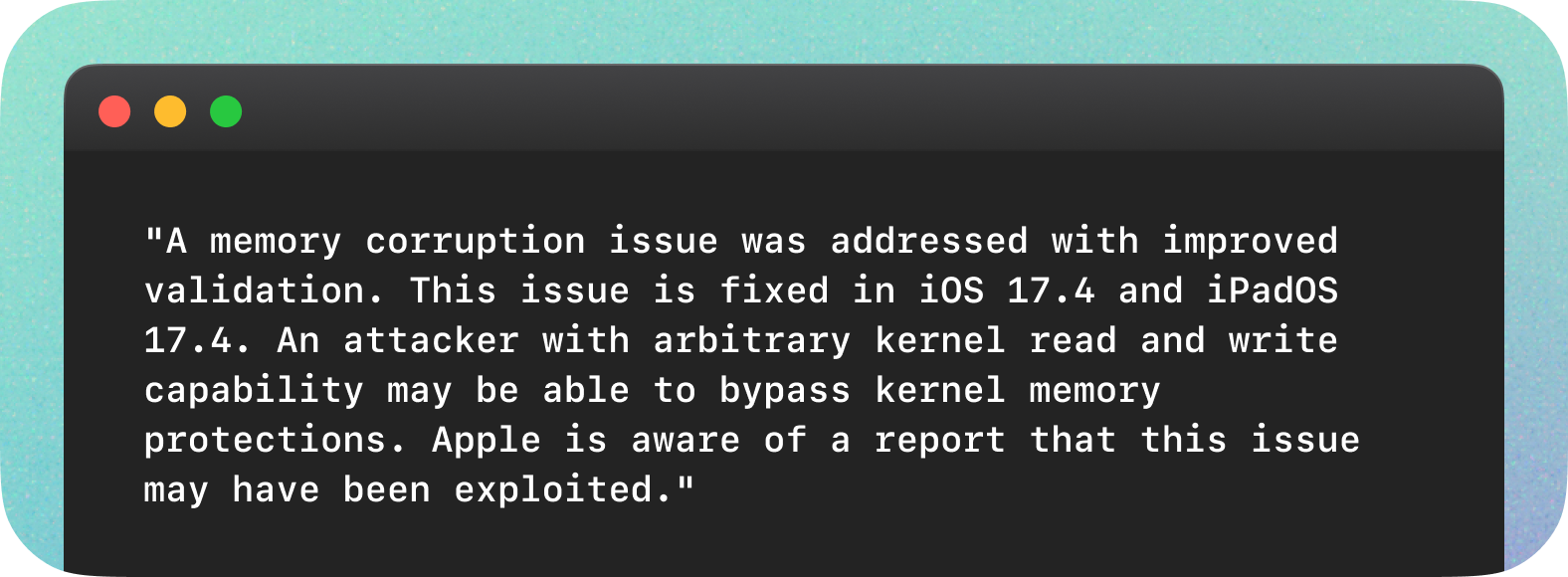
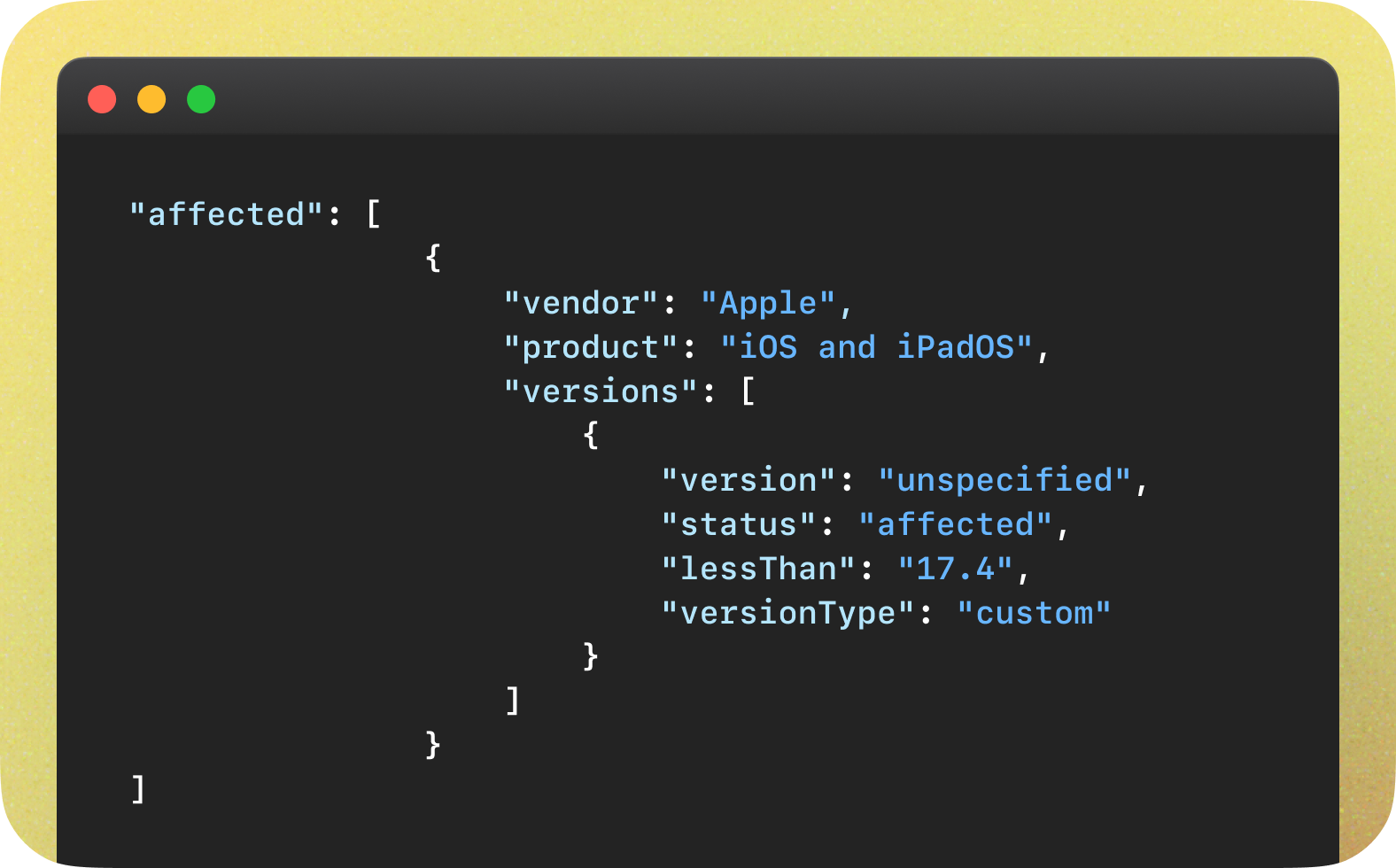
Instead, NVD expanded the affected software configuration to include all the versions of Apple operating systems.
CVE-2024-30273
CVE-2024-30273 is an example of a vulnerability description disagreeing with the machine-readable affected configuration description. While the description explicitly mentioned two affected major versions, the affected versions block only references one.
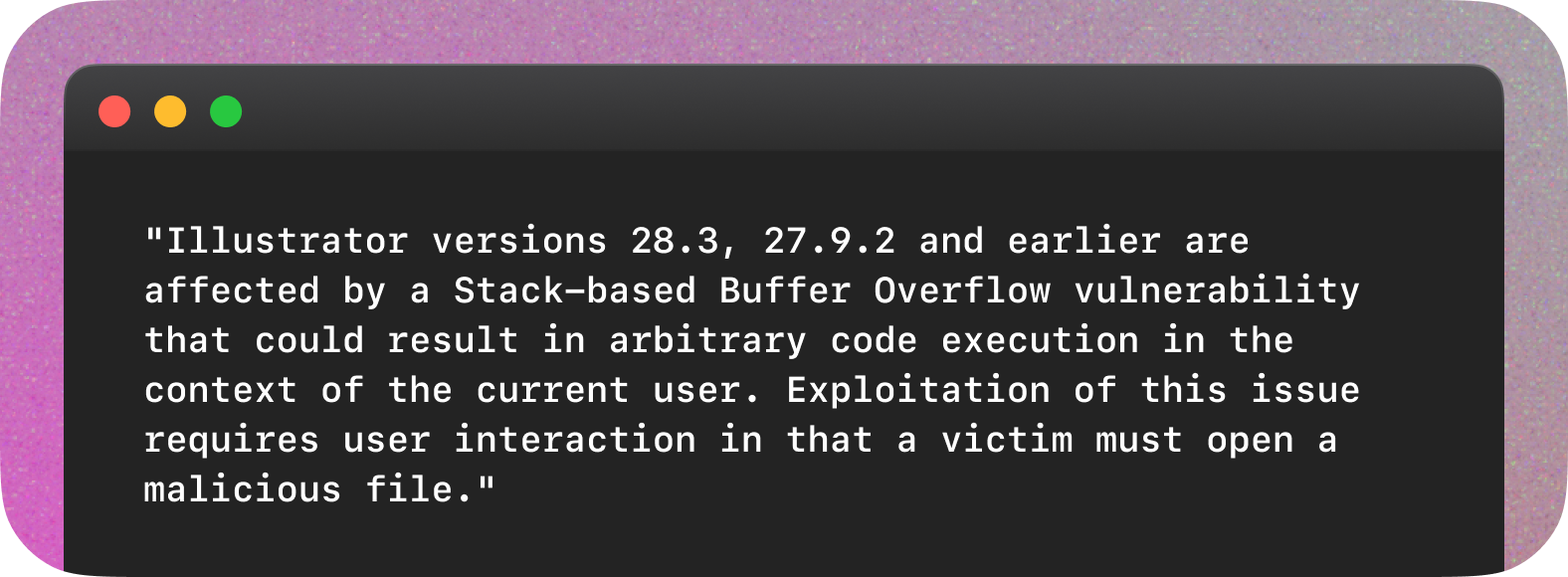
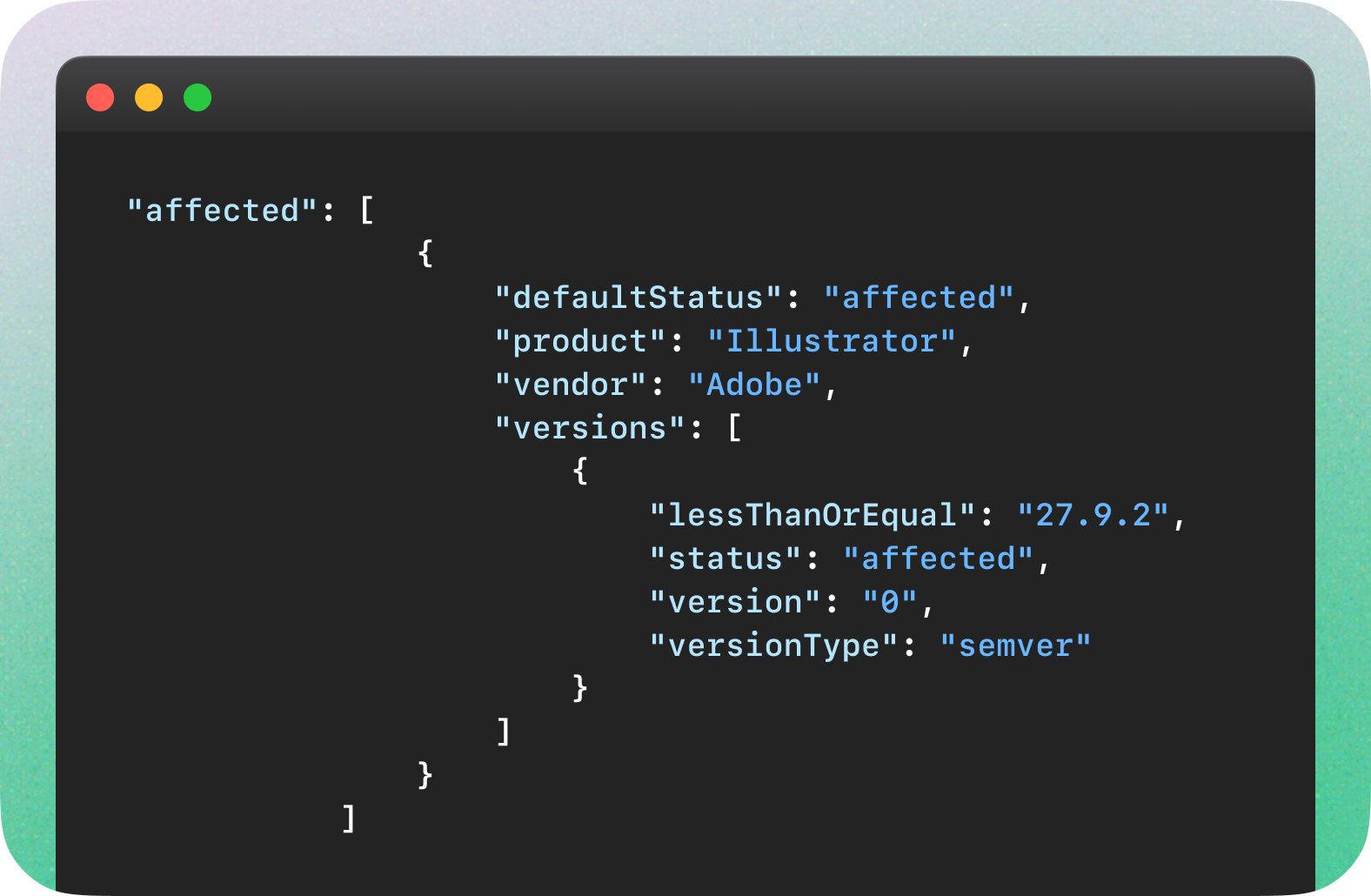
Unfortunately, NVD didn’t provide any enrichment for this CVE, so there is no second source to check which record might be more correct.
Anyway, these examples clearly show that no automation can cover this type of discrepancy in the CNA provided CVE records without expert human oversight.
Different ways to encode the affected configurations
Various CNA use different encoding logic for affected versions. Here are just a few examples that aim to illustrate the diversity of approaches and challenges of making sense from this data in an automated manner.
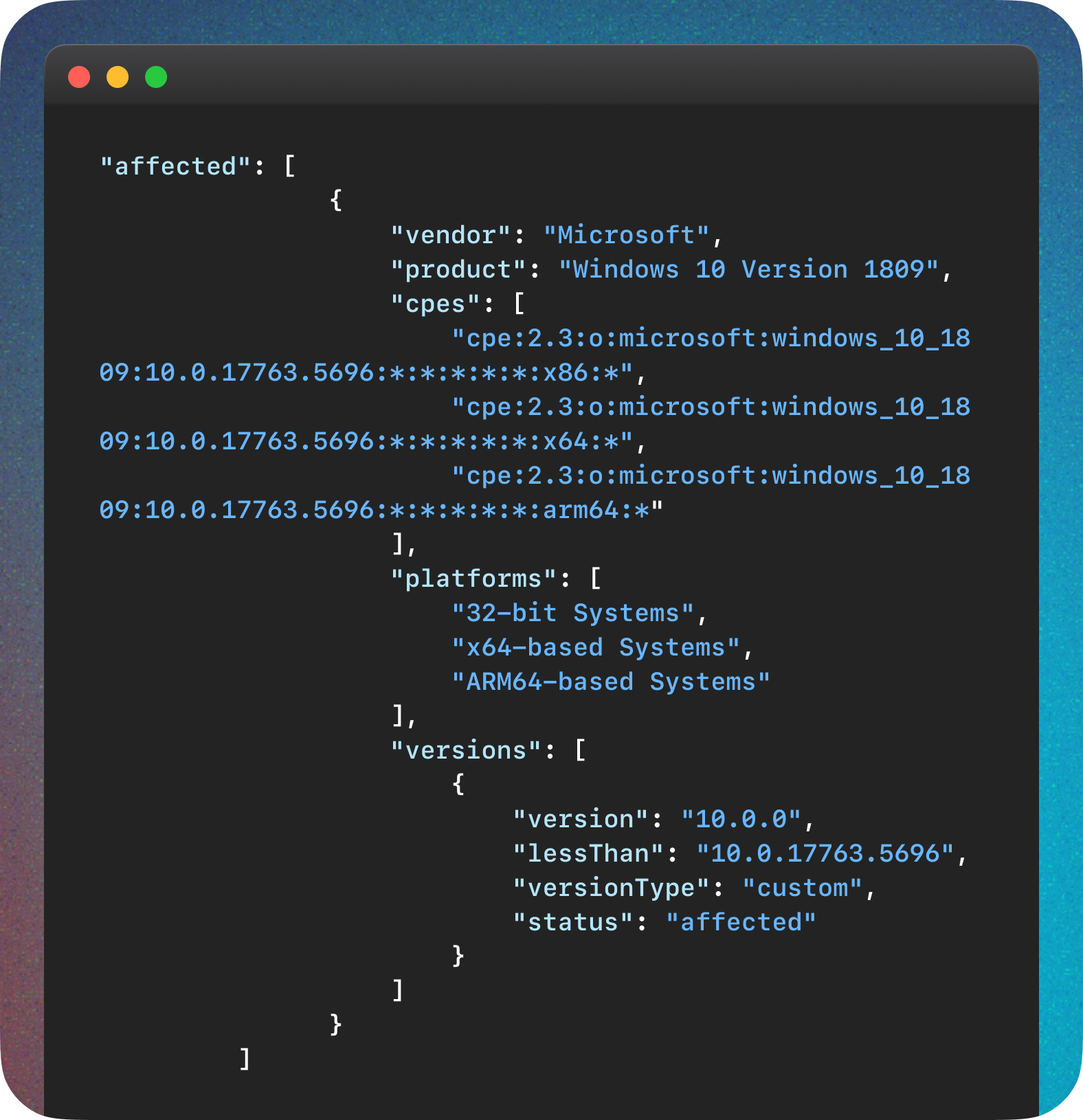
Microsoft, CVE-2024-29988
We start here with a positive example. Microsoft appears to be one of the most accomplished CNAs, providing very detailed affected software information that includes well-formed CPEs. Here is an abbreviated example from CVE-2024-29988.
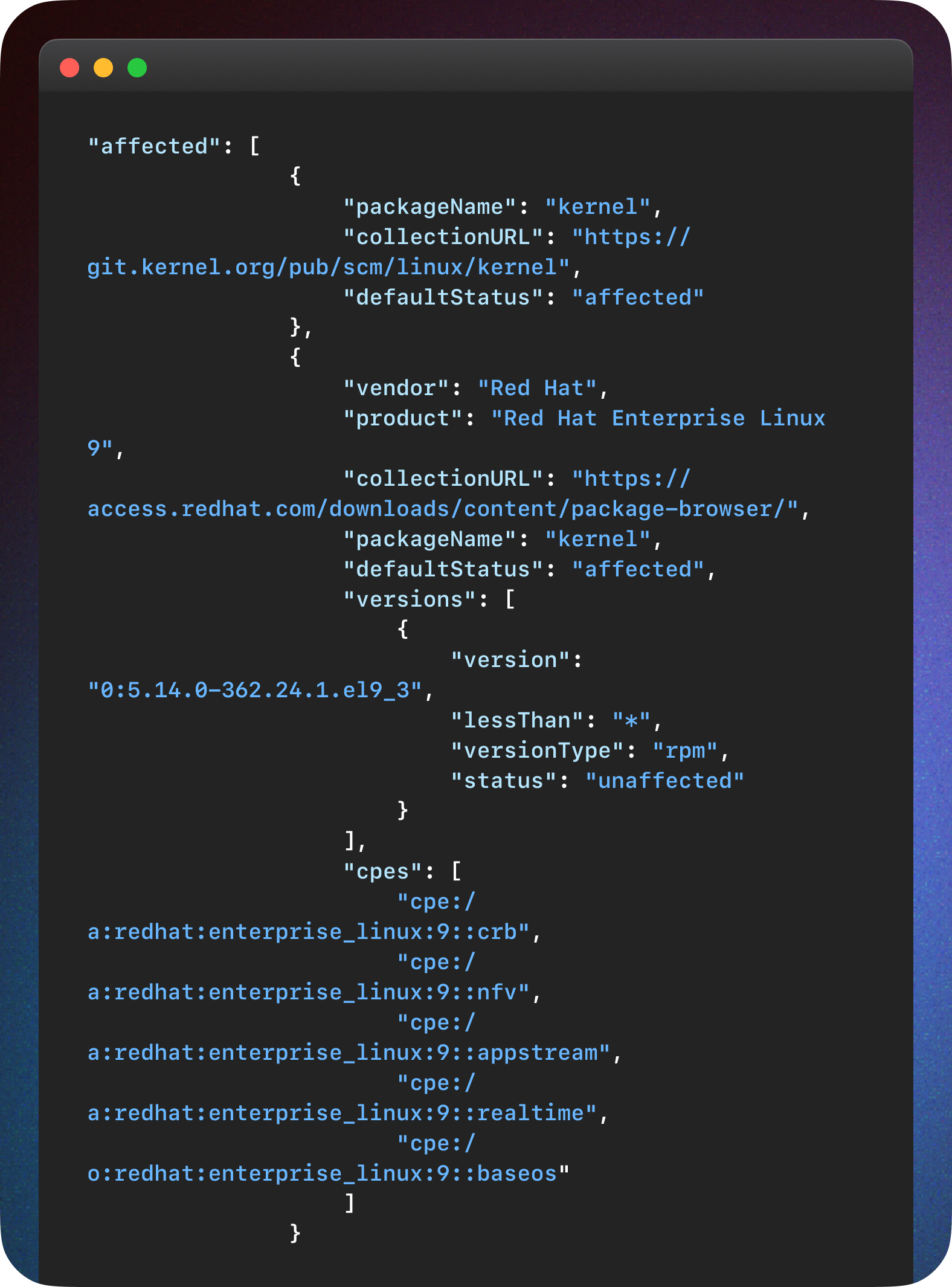
Red Hat, CVE-2024-0193
Red Hat is another CNA that provides quality affected software configurations, but they seem to use a different set of fields of CVE Record format for that. Here is again an abbreviated example for CVE-2024-0193.
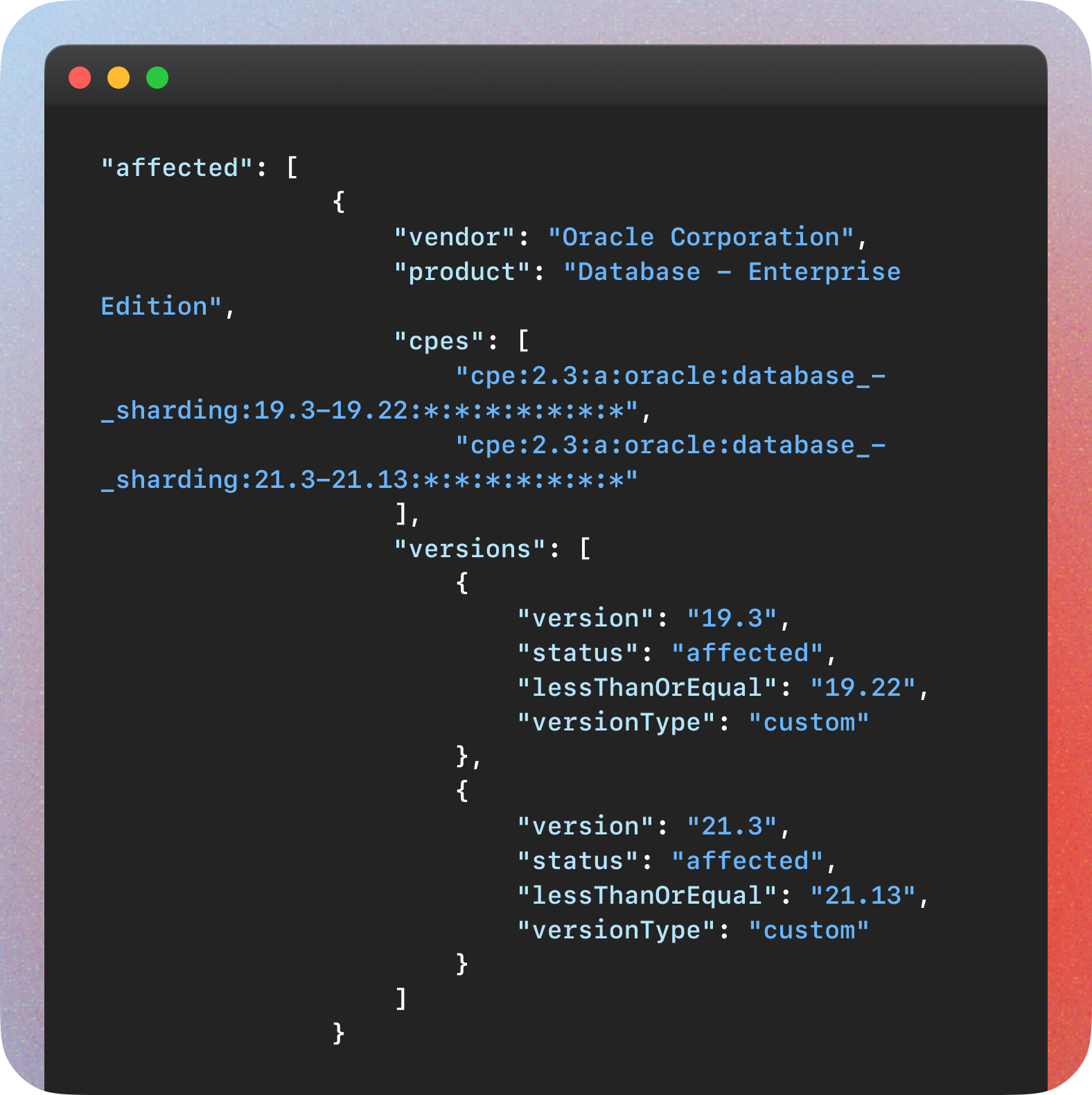
Oracle, CVE-2024-20995
Oracle has been proving consistently looking affected software structures, and recently also started providing CPE for the vulnerabilities they publish, which for us sometimes look a bit unconventional. Here is an example for CVE-2024-20995.
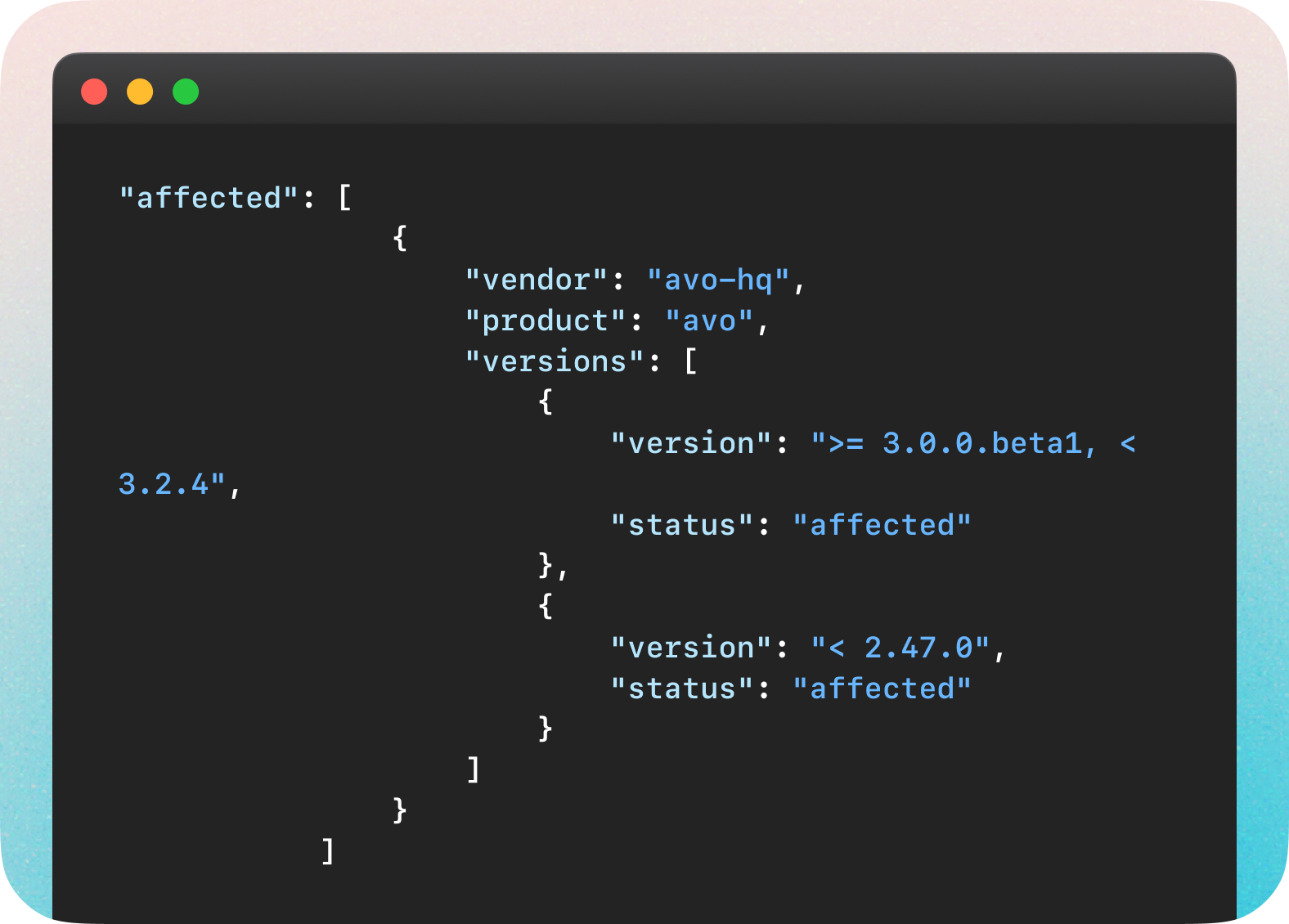
GitHub, CVE-2024-22191
GitHub currently only covers CVEs requested by software maintainers using the GitHub Security Advisories feature, focusing on open-source software. While their data are mostly complete and human-comprehensible, one would have difficulty automating analysis of affected information like this (CVE-2024-22191).
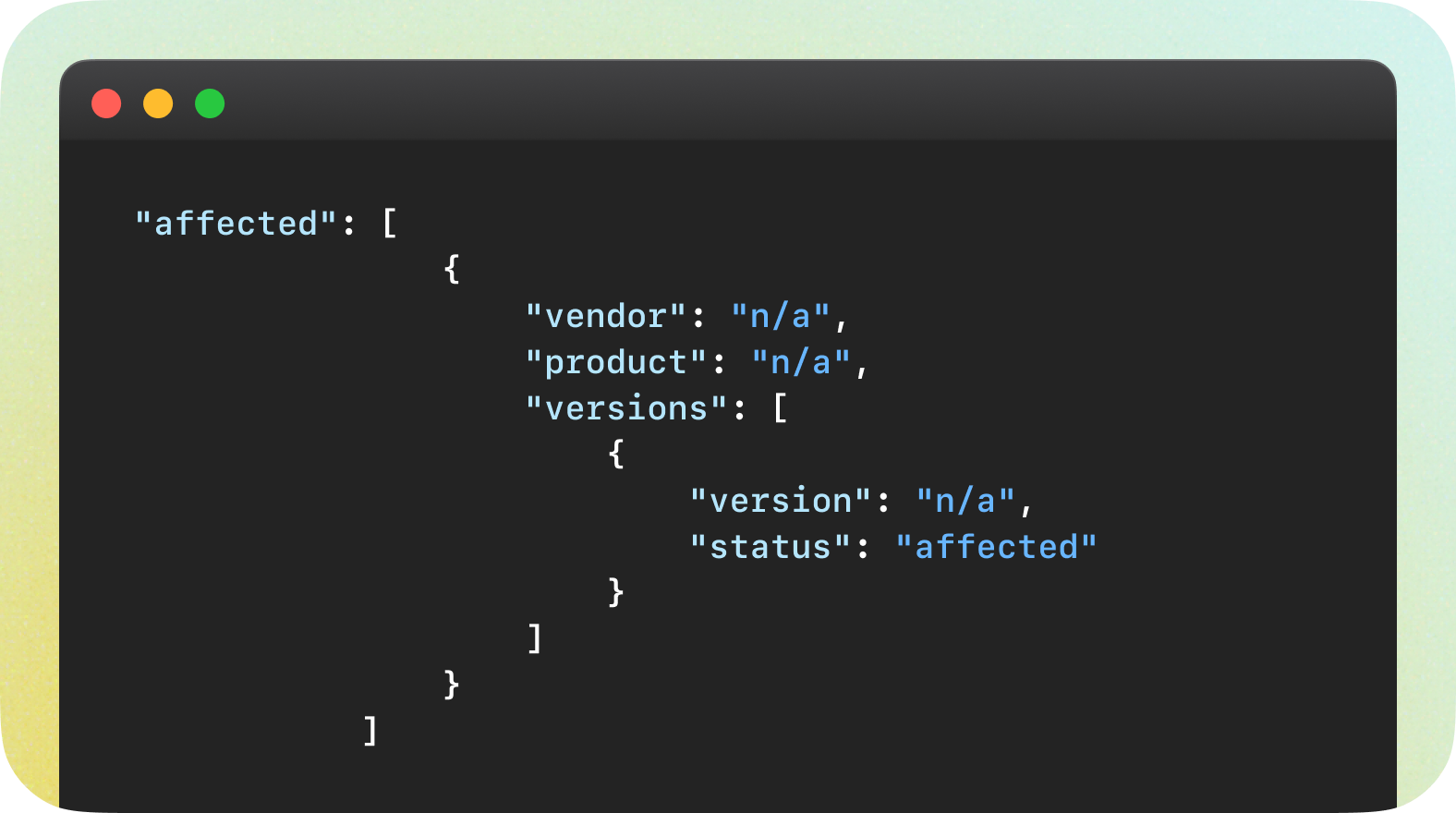
MITRE, CVE-2024-21732
To illustrate a point made earlier in this article, a typical MITRE affected section looks like this.
In a recent blog post, the CVE Program encouraged CNAs to push forward to improve the completeness and accuracy of provided data. We hear that the work is underway in the CNA community to learn and pick up the best practices. Still, for many it will take up to a few months to get on par with the best ones like Microsoft, Red Hat, and GitHub.
The Limits of Current Automation and AI in Handling Data Noise
Given the variability and noise inherent in the data provided by CNAs, relying solely on automated systems and even advanced machine learning models, such as Large Language Models (LLMs), proves insufficient.
Relying on generative models here probably would be specifically problematic. The chances that a model will substitute an affected configuration it saw in the learning set or will hallucinate it altogether are non-trivial. These technologies, while helpful, cannot yet replace the nuanced understanding and critical judgment required to interpret vulnerability data accurately.
As the concluding example, let’s take a look at CVE-2024-34517, which was published via MITRE with minimal accompanying information, literally a description and a few references. Without a definitive source of truth, various vulnerability data sources had to come up with affected configurations on their own. Many show no info, but where it is available data varies widely — see just a few examples here, here, and here.
We are not trying to judge who is right in this particular case, and have no insight into how these configurations were created. But the reality is that automated systems must be supplemented by human expertise, and that highlights a significant gap in the current technological landscape of vulnerability management.
Vulners' Approach to Data Normalization
In response to these challenges, Vulners has implemented specific handlers for handling data from key CNAs that are pivotal to the market and produce a large volume of CVEs.
By developing customized handlers, Vulners can generate normalized CPE and version ranges, transforming raw data into structured, actionable information. This approach not only enhances the accuracy of our vulnerability database but also streamlines the process for security teams relying on our data.
The Ongoing Challenge and the Path Forward
All these examples show that the field of vulnerability management is far from achieving a solution that entirely eliminates the need for manual oversight in creating vulnerable software configurations based on available information.
The complexity and diversity of data provided by CNAs mean that exceptions and unique cases will continue to challenge even the most sophisticated automated systems.
The path forward involves a combination of improved data quality and coverages from CNAs (surely with humans in the loop), and perhaps most critically, continued reliance on the expert analysis by cybersecurity professionals.
Conclusion
This overview shows that there is no way forward that wouldn’t involve manual work, and full automation of the solution is impossible without nuanced data analysis. Vulnerable software configurations in an easily consumable CPE form used to be delivered only by NVD, but now to get that information, you have to parse each vendor provided data separately.
Vulners remains committed to refining our methods and tools. While we have made significant progress in managing and normalizing data from key CNAs, the broader challenges of ensuring reliable, automated vulnerability assessments persist.
We welcome feedback from the community to help us evolve our strategies and contribute to developing more robust solutions capable of navigating the complexities of today's cybersecurity challenges.