Downloading entire Vulners.com database in 5 minutes
8.1 High
CVSS3
Attack Vector
NETWORK
Attack Complexity
HIGH
Privileges Required
NONE
User Interaction
NONE
Scope
UNCHANGED
Confidentiality Impact
HIGH
Integrity Impact
HIGH
Availability Impact
HIGH
CVSS:3.0/AV:N/AC:H/PR:N/UI:N/S:U/C:H/I:H/A:H
9.3 High
CVSS2
Access Vector
NETWORK
Access Complexity
MEDIUM
Authentication
NONE
Confidentiality Impact
COMPLETE
Integrity Impact
COMPLETE
Availability Impact
COMPLETE
AV:N/AC:M/Au:N/C:C/I:C/A:C
0.975 High
EPSS
Percentile
99.9%
Today I once again would like to talk about Vulners.com and why, in my opinion, it is the best vulnerability database that exist nowadays and a real game-changer.
The main thing is transparency. Using Vulners you not only can search for security content (see “Vulners – Google for hacker”), but download freely all available content from the database for your own offline analysis. And more than this, you can even see how Vulners actually works and evaluate how fresh and full the content is.

Why you may need to download full security content database? For example, you may want to create something like vulnerability quadrants.
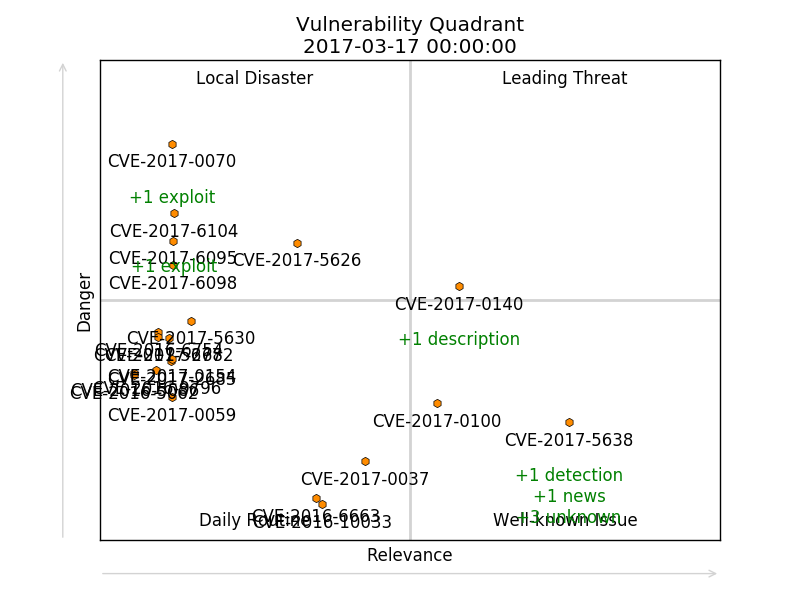
For this I needed to get CVE objects with all related security objects of other type. This information you can see it on any CVE web page on vulners.com, e.g. CVE-2017-0144.
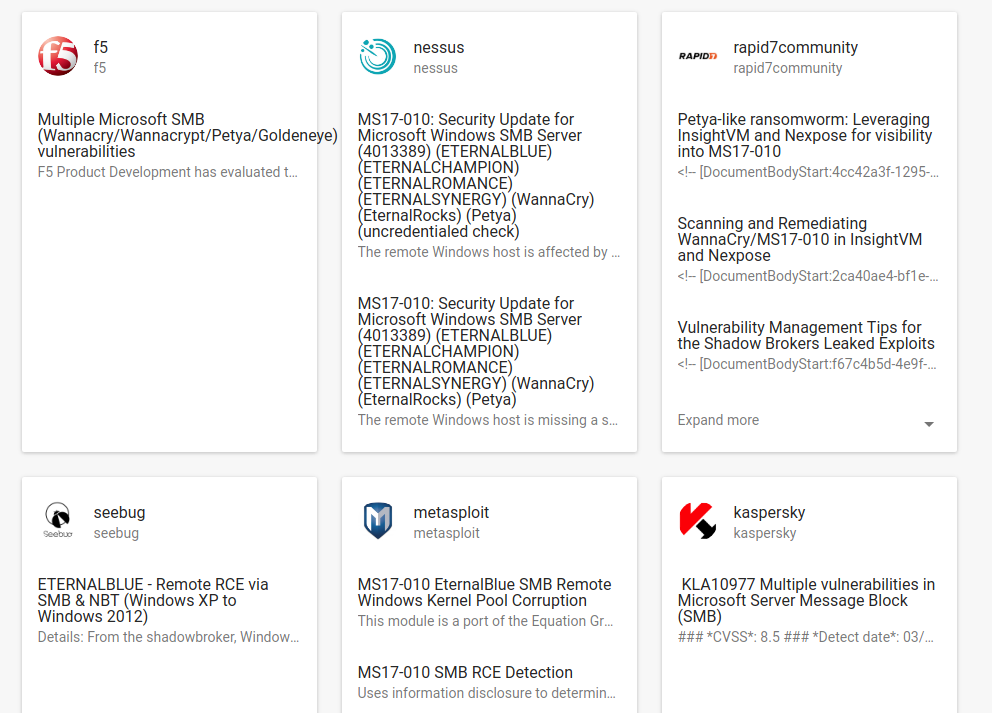
You can get it using search API:
https://vulners.com/api/v3/search/id/?id=CVE-2017-0144&references=true
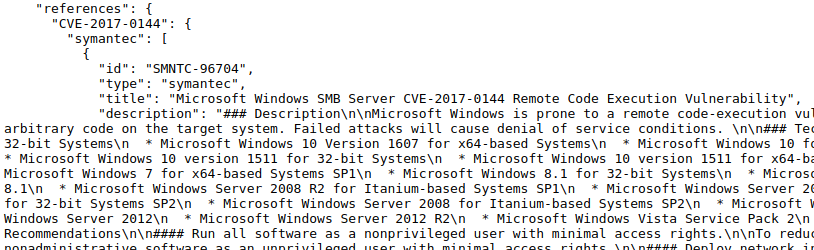
The problem is that you will need to do it for each CVE. That mean you will need to make enormous amount of requests. It’s not a very efficient process. Of course, it would be good if we had all these links to security objects in CVE Vulners collection (see “Processing Vulners collections using Python”). But unfortunately these data is dynamic currently is not available in Vulners archives/collections.
So, the other option is to download all available security object collections and process it from the own scripts.
First of all we need to get available security object types. You can do it with a simple get request to <https://vulners.com/api/v3/search/stats/>
{
"result": "OK",
"data": {
"type_results": {
"**aix**": {
"lastUpdated": [],
"bulletinFamily": "unix",
"displayName": "IBM AIX",
"lastrun": "2017-08-09T19:06:26",
"count": 108,
"workTime": "0:00:12.061442"
},
You can download all collections in multiple parallel threads using Python code bellow. I created eventlet.GreenPool() element and ran pool.imap(download, object_names) with a link to a worker function, that downloads Vulners collection, and the set of available object_names (cve, nessus, openvas, redhat, centos, aix, etc.). Parallel launching of the tasks will be managed automatically.
#pip install eventlet
import requests
import json
import eventlet
import os
response = requests.get('https://vulners.com/api/v3/search/stats/')
objects = json.loads(response.text)
object_names = set()
for name in objects['data']['type_results']:
object_names.add(name)
def download(name):
response = requests.get('https://vulners.com/api/v3/archive/collection/?type=' + name)
with open('vulners_collections/' + name + '.zip' , 'wb') as f:
f.write(response.content)
f.close()
return name + " - " + str(os.path.getsize('vulners_collections/' + name + '.zip'))
pool = eventlet.GreenPool()
for name in pool.imap(download, object_names):
print(name)
Download function prints collection name and the size of Vulners collection zip file. The whole job finished in 5 minutes:
xen - 83878
d2 - 15998
typo3 - 156251
samba - 27866
pentestit - 21909
malwarebytes - 143380
archlinux - 327987
...
openbugbounty - 12500426
korelogic - 68225
w3af - 229716
gentoo - 899848
fireeye - 449874
pentestnepal - 10921
wired - 7242
debian - 3421840
carbonblack - 101328
metasploit - 4541274
zeroscience - 954521
hackread - 16768
appercut - 474561
thn - 5029563
freebsd - 1303269
The total download time will, of course, depend on your Internet connection speed and the current workload on Vulners.com.
Downloaded zip archives:
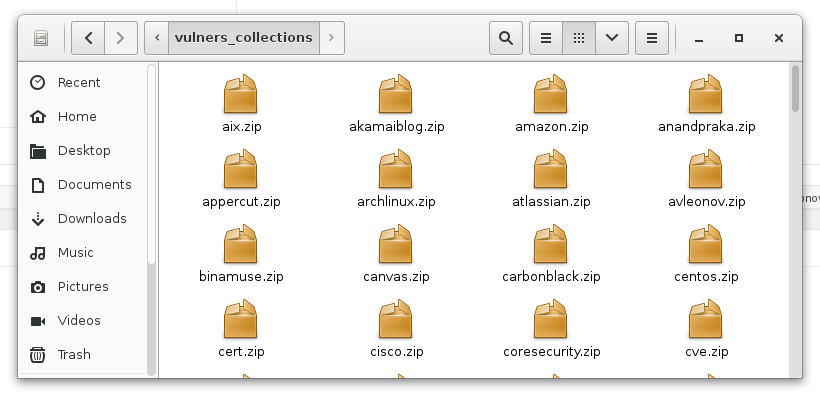
The whole size:
# du -h vulners_collections/ 374M vulners_collections/
How to work with this collection files read in Processing Vulners collections using Python.
Related
8.1 High
CVSS3
Attack Vector
NETWORK
Attack Complexity
HIGH
Privileges Required
NONE
User Interaction
NONE
Scope
UNCHANGED
Confidentiality Impact
HIGH
Integrity Impact
HIGH
Availability Impact
HIGH
CVSS:3.0/AV:N/AC:H/PR:N/UI:N/S:U/C:H/I:H/A:H
9.3 High
CVSS2
Access Vector
NETWORK
Access Complexity
MEDIUM
Authentication
NONE
Confidentiality Impact
COMPLETE
Integrity Impact
COMPLETE
Availability Impact
COMPLETE
AV:N/AC:M/Au:N/C:C/I:C/A:C
0.975 High
EPSS
Percentile
99.9%