No left boundary for Vulnerability Detection
It’s another common problem in nearly all Vulnerability Management products. In the post “What’s wrong with patch-based Vulnerability Management checks?” I wrote about the issues in plugin descriptions, now let’s see what can go wrong with the detection logic.
The problem is that Vulnerability Management vendors, in many cases, have no idea which versions of the Software were actually vulnerable.
OMG?! How this can be true?  Let’s take an example.
Let’s take an example.
Each vulnerability at some points in time:
- was implemented in the program code as a result of some mistake (intentional or not)
- existed in some versions of the program
- was detected and fixed
Read more about this in “Vulnerability Life Cycle and Vulnerability Disclosures”.

Let’s suppose that we have some Software A with released versions 1, 2 … 20.
Just before the release of version 10, some programmer made a mistake (bug) in the code and since the version 10 Software A has become critically vulnerable. Before the release of version 20, Software Vendor was informed about this vulnerability and some programmer fixed it in version 20. Then Software Vendor released a security bulletin: “Critical vulnerabilities in the Software A. You are not vulnerable if you have installed the latest version 20.”
And what does Vulnerability Management vendor? This vendor only sees this security bulletin. It is logical for him to decide that all versions of Software A starting from 1 are vulnerable. So, it will mark installed versions 1 … 9 of the Software A as vulnerable, even so actually they are NOT.
In real life
Here is, for example, a typical Ubuntu Linux security bulletin USN-3783-1: Apache HTTP Server vulnerabilities with simple logic: if you have in Ubuntu 18.04 LTS package apache2-bin with the version bigger than 2.4.29-1ubuntu4.4, this mean that you are NOT vulnerable.
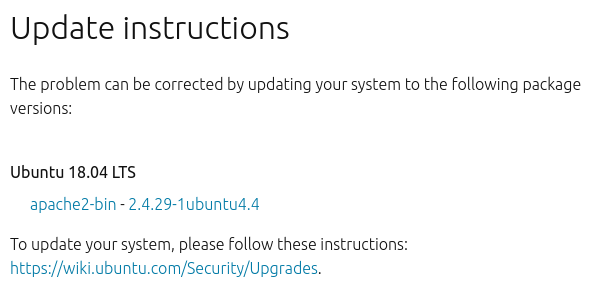
If you have smaller version of the package, than you are vulnerable. How smaller? It’s clear that there was a moment when this vulnerability was implemented. In Ubuntu change log for apache2 there are 344 versions since 2001. Which versions are vulnerable with USN-3783-1?
Nobody actually knows. And nobody interested in detecting this in practice, because it’s too complicated. It’s much easier to mark everything that is smaller than 2.4.29-1ubuntu4.4 (btw, comparison of the versions is not trivial!) as vulnerable version and don’t pay too much attention to it.
Will it be a false positive? Of course yes! Can it be fixed? Well…
From the Software Vendor side
Of course, this is not really the fault of Vulnerability Management vendors, but rather Software Vendors, who, in most cases, do not provide clear information which versions of their software are vulnerable.
But why should they? All they have to do is to inform how to use their product safely: install the latest software version or certain patches. And that’s all.
From the Vulnerability Management Vendor side
Vulnerability Management vendors could find “left boundaries” on their own. To do this, they should obtain all distributions of Software A, deploy them and try to exploit the vulnerability. On which version the exploit stops working, that version is not vulnerable.
But here are the following problems:
- exploits exist for a very small number of vulnerabilities
- it’s hard to support this huge testing infrastructure
- even if the exploit did not work well, it is unclear whether the version is not vulnerable or it’s a problem with particular exploit
And why should Vulnerability Management vendors spend their resources on this? Only for limiting number of false positives in the scan results?
I think it doesn’t really motivate them, because
- most of the users are not interested in how vulnerability detection works and they are not aware of the problem
- another big part of users is satisfied with the quality of the detection: yet another software update will not hurt, even if it was not necessary
- those who understand and who are not satisfied with the quality of the detection won’t be able too prove that the version is not vulnerable: if it were so easy, the vendors would do it by themselves

The maximum that vendors can do is to limit the vulnerable versions on the left by first major version. This, on the other hand, can lead to false negative errors.
In conclusion
As a result, the vulnerabilities that were detected in “Vulnerability Management” process become not real and exploitable, but very potential. And system patching become not an emergency measure, but rather formal procedure, that need to be done mainly for fulfilling requirements of regulators. This makes a lot of difficulties in negotiations with IT, if they are not ready to update their systems constantly, just because the scanner shows that the installed software is vulnerable.